팀에서 카프카를 사용한다는데 도대체 이야기를 이해하기 힘들어서 공부하면서 포스팅 하기로 함
Before Kafka

처음에는 앱간 데이터 전송은 단순한 Source -> Target 단방향 통신으로 시작했으나 Source, Target 앱 개수가 많아지면서 데이터 전송 라인이 매우 많아짐.
=> 데이터 전송 라인이 많아지면 앱 배포와 장애에 대응하기 어려워짐
=> 타깃 애플리케이션 장애시 그대로 소스 애플리케이션으로 장애 전파
=> 데이터 프로토콜 파편화가 심해짐(데이터 포맷에 변경이 생기면 온군데에다가 다 수정해줘야함)
After Kafka

- 아파치 카프카는 LinkedIn 데이터팀에서 만든 신규 시스템으로 Source와 Target 사이의 Coupling을 느슨하게 결합시켜 Source는 카프카에 데이터 전송만 하면 되고, Target은 카프카에서 데이터만 가지고 오는 단순한 구조로 바뀐다.
- 카프카를 통해 전달할수 잇는 데이터 포맷 제한은 없다. 직렬화, 역직렬화를 통해 ByteArray로 통신하기 때문에 자바에서 선언 가능한 모든 객체를 사용할수 있다.
- 상용환경에서 카프카는 최소 3대 이상의 브로커(카프카 서버)에서 분산 운영하며, 프로듀서를 통해 전송 받은 데이터를 기록하기 때문에 일부 브로커에 장애가 생기더라도 안전하게 운영할수 있다.
- 데이터를 묶음 단위로 처리하는 배치 전송을 통해 낮은 지연과 높은 데이터 처리량을 가진다.
데이터 레이크
현대의 IT 서비스는 기록 가능한 모든 것을 저장한다.
- 쇼핑몰의 결제내역, 방문한 위치 정보, 댓글 등등
- 실시간으로 저장되는 데이터의 양이 테라바이트를 넘어 엑사바이트를 웃돈다. 이것을 빅데이터라고 부른다.
- 기존 DB에서 사용하던 스키마 기반의 데이터 뿐만 아니라 규격이 없는 비정형 데이터까지 포함
- 데이터 레이크는 데이터가 모이는 저장공간으로 필터링되거나 패키지화되지 않은 데이터가 저장한다. (운영되는 서비스로부터 수집 가능한 모든 데이터를 모음)
- 빅데이터를 잘 활용하기 위해서는 안정적이고 확장성이 높은 데이터 파이프라인을 구축하는 것이 중요하다.
- 데이터 파이프라인을 구축하지 않고 일회성으로 구축한 데이터 수집은 데이터 흐름의 파편화로 이어지고 반복적인 유지보수로 개발자를 괴롭힌다.
이때 가장 좋은 방법 중 하나가 아파치 카프카를 이용하는 것
아파치 카프카의 장점
- 높은 처리량
동일한 양의 데이터를 보낼 때 네트워크 통신 횟수를 최소한으로 보내면 더 많은 데이터를 보낼수 있다.
아파치 카프카는 데이터를 보낼 때 모두 묶어서 전송하여 대용량의 실시간 로그데이터를 처리하는데 적합하고 파티션 단위를 통해 동일 목적의 데이터를 여러 파티션에 분배하여 병렬로 처리할수 있다.
- 확장성
클러스터의 브로커 개수를 늘려 스케일 인, 아웃을 자유롭게 할 수 있다.
- 영속성
다른 메시징 플랫폼 시스템과 다르게 메모리가 아니라 파일 시스템에 저장한다.
- 고가용성
일부 서버에 장애가 발생하더라도 무중단으로 지속적인 운영이 가능하다.
(여러 브로커에 데이터가 복제되어 저장되므로 하나의 브로커가 장애가 되더라도 처리 가능)
on-premise, public cloud 환경에서 모두 동작 가능
데이터 레이크 아키텍처
람다 아키텍처
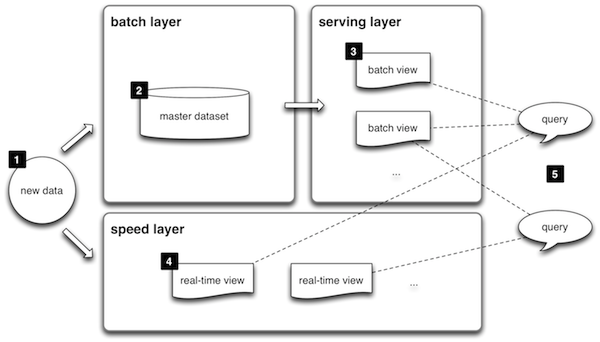
기존의 문제점
실시간으로 생성되는 데이터들을 처리하기 힘듬
원천 데이터의 히스토리를 파악하기 힘듬
데이터 파편화로 데이터 거버넌스를 지키기 어려워짐
배치 레이어
- 배치 데이터를 모아 특정시간 타이밍마다 일괄 처리한다.
서빙 레이어
- 가공된 데이터를 이용할수 있도록 데이터를 저장하는 공간
스피드 레이어
- 서비스에서 생성되는 원천 데이터를 실시간으로 분석하는 용도 => 카프카가 이에 해당됨
람다 아키텍처의 단점
- 데이터를 처리하는 레이어가 2개로 나뉘어 필요해 레이어마다 로직을 따로 만들어야함
- 배치데이터 + 실시간을 같이 처리할떄 유연하지 못함
카파 아키텍처

특징 : 배치 레이어 없이 모든 데이터를 스피드 레이어에서 처리함
단, 서비스에서 생성되는 모든 데이터를 스트림 처리해야한다.
배치 데이터 : 기간 단위 데이터 ex) 지난 1분간 주문한 제품목록 2021년 신입생 목록
스트림 데이터 : 한정되지 않은 데이터, 시간과 끝이 명확히 정해지지않음 ex) 웹 사용자의 클릭 로그, 사물 인터넷의 센서 데이터

- 모든 데이터를 로그로 바라봄
- 애플리케이션을 로깅하는 텍스트 로그가 아닌 데이터의 집합. 지속적으로 추가가능하며 각 데이터에는 일정 번호가 붙는다.
- 로그로 배치데이터와 스트림 데이터를 저장 사용하기 위해서는 변환 기록이 일정기간 삭제되어서는 안 되고 지속적으로 추가되어야한다.
스트리밍데이터 레이크
- 2020년 카프카 서밋에서 제이 크랩스는 카파 아키텍쳐에서 서빙 레이어를 제거한 아키텍처인 스트리밍 데이터 레이크(Streaming Data Lake)를 제안 했다.
- 카프카를 통해 프로세싱한 떼이터를 굳이 다시 서빙 레이어의 저장소에 저장하지 않고, 스피드 레이어에서 사용되는 카프카에 오랜기간 저장하고 사용한다.
- 데이터의 중복 비정합성 문제 해결, 레이어를 줄임으로써 운영 리소스 줄임
- 자주 접근하지 않는 데이터를 카프카 클러스터가 아닌 값 싼 스토리지에 저장하고 자주 사용하는 데이터만 카프카 브로커에서 사용하는 구분작업이 필요하다.
- 카프카의 데이터를 쿼리할수잇는 플랫폼 ( ksqlDB)
- apache spark streaming + 프레스토 + 하이브 + 아파치 드릴 + 스파크 sql 조합 등 서드 파티 툴들과 카프카를 연동하여 사용